

지난 5년간 Papers라는 앱을 이용하여 전반적인 문헌관리를 하고 있었다. 여기서 전반적이라는 말은 문헌을 쌓아두고, 참조 및 분류작업이후 지속적이고 점진적으로 문헌을 참고하는 작업을 이야기한다. 실제 집필에 사용되는 환경은 Emacs + LaTeX이고 한번 참고문헌 리스트를 bib파일로 추출된 다음에는 betterbib 및 Emacs의 RefTeX를 사용하게 되므로 문헌관리 시스템 전체가 Papers에 의존하고 있는 상황은 아니다. 또한 일상적으로 조각난 연구노트의 경우 Devonthink를 이용하여 자체적으로 분류한 번호를 이용하기에 이 역시 Papers의 역할은 비교적 제한적이라고 할 수 있다. 그럼에도 불구하고, 연구진행 전반에서 문헌을 참고하는 과정에서는 늘 Papers를 사용하게 되므로 이를 통해 구축한 DB와 그 속에서 내부적으로 그리고 히스토리에 따라 분류된 Group은 나의 워크플로우에서 핵심을 이루고 있다.
처음 Papers를 사용한것은 사실 아이패드로 2버전을 이용한 것이었는데, 이 때는 리눅스/윈도우기반으로 주로 작업을 했기에 Mendeley를 기준이 되는 문헌관리 시스템을 사용하였다. 시간이 지난후, 개인용 및 연구용 시스템 모두를 맥 환경으로 이전한 약 5년 전부터는 Papers 3 으로 모든 관리시스템을 통합했고 그게 지금까지 이어지고 있는 상황이다. 이 기간동안 쌓아온 참고문헌들은 그 상당수가 지하실 창고와 같이 어지럽게 쌓여있고, 개인 히스토리와 관련되어 분류된 Group을 경우 그 계층의 깊이가 상당히 들쭉날쭉해지면서 자주 사용하는 Group을 제외하고는 기억에 의존하여 Papers내부의 검색기능을 주로 활용하게 되는 등 내부 DB구성에 대해 한번 쯤 정리가 필요한 상황에 있었다.
Papers은 오랫동안 판올림을 통해 다채로운 기능들을 제공해주고 있었다. 레거시로 남은 Papers 3을 잦은 충돌에서 불구하고 여전히 사용하고 있었던 이유 역시 단순한 관성이 아니라, 새로운 대체품을 찾는데 어려움을 겪고 있었기 때문이다. 새로운 Readcube-Papers의 구독형 및 클라우드 서비스는 온라인 기반으로 이루어지고 제한적 기능에 대한 preview app만을 제공하고 있다. 현재 학계의 저널 시스템들 역시 기존의 pdf/web 이원화 방향에서 점차 반응형 통합 시스템으로 바뀌고 있다보니 Readcube의 새로운 방향은 잘만 발전한다면 시기적절한 움직임이라고 할 수 있다.
하지만 필자 개인적인 집필 환경에는 이러한 변화들이 모두 바람직하다고 이야기 할 수는 없다. 레거시로 넘어가면서 더이상 업데이트가 진행되지 않는것은 둘째치고, 잦은 충돌로 인내심을 잃어가기 시작한지가 벌써 일년쯤 되었고 다음 판올림에 해당되는 Readcube-Papers 서비스는 현재 기준으로는 필자에게 필요한 오프라인 서비스가 제한적으로만 지원되는 한계를 가지고 있다. 덧붙여, 이후 본격적인 stand-alone app이 나오고 Papers 3이상의 여러가지 기능을 제공하게 되더라도 전반적인 행보가 온라인 시스템을 가르키고 있기에 그 기대치마저 낮아지고 있는 상황이었다. 개인적인 선호도로는 PDF파일들을 바탕으로 메모도 하고 OS X의 태그시스템과 효과적으로 결합하면서 기존의 bibtex의 사용성을 해치지 않는 방향으로 나아가고 싶었다. 물론 JabRef를 생각할 수 있겠지만, 이미 Emacs에서 RefTeX를 이용하고 있고 몇가지 미흡한 부분들은 Python으로 구성된 Betterbib package를 사용하고 있으므로 굳이 많은 부분이 중복적인 기능이 되는 문헌관리 시스템을 구성하고 싶지는 않았다. 결국 오프라인을 바탕으로 사용하는 시스템간의 상호 연결성과 장기 신뢰성을 확보하는 솔루션이 필요한 상황이었다. 워크플로우 내에서의 각 구성요소들은 점진적으로 바뀌기도 하고 경우에 맞춰야 하는 경우도 있고 (예를들어 연구과제 리포트에 관련된 공동작업등은 여전히 MS Word를 이용하고 있다) 결과적으로 집필환경은 구성요소와 각 구성요소의 연결방법은 동적이다. 이러한 동적환경에서, 도구들에 크게 구애받지 않고 하고자 하는 일을 하려면, 조금씩 다를 수 있는 상황에서도 적용가능한 공통적인 습관들을 어느정도 유지해야 할 필요가 있다.
사실 기존의 Papers 3의 경우에도 필자가 원하는 방향의 대부분의 기능을 제공했지만, 늘 앱의 디자인 철학이 앱 자체내로 고립되는것을 유도하는 느낌을 받곤 했다. 예를들어 맥에서 지원되는 Tag가 아니라 자체 Keyword 시스템을 운용하는것, 동기화 설정이 켜져있는 경우 첨부파일이름을 자체 DB의 이름으로 바꾸고 virtual folder에서 우리가 인식가능한 이름으로 볼수 있게 만드는 방식등이 있다. 무엇보다도 중요한 것은, 문헌관련해서 노트 및 하이라이트등이 앱 자체내에서만 참조할 수 있는 방식이다. 앱 하나로 필요한 대부분을 지원해주고, 대신 앱 내부에서의 사용성을 극대화한다는 방법은 나름의 장점이 많은 방식이고, 첫 버전의 Papers의 환경을 생각해보면 그 당시 Mac OS에서 지원되지 못한 다양한 기능들을 앱 자체적으로 구현하고자 한 노력의 경로라 생각한다. 문제는 신기할정도로 불안정한 시스템인데, 예를들어 위에 언급한 대부분의 문제를 해결 해 줄수 있는 핵심적인 시스템으로 virtual folder기능을 활용할 수 있는데 이 시스템의 장점은 둘째문제고 갖은 detach상태는 사실상 Devonthink와 같은 다른 DB에서 분류해서 사용하기 힘든 환경을 제공하게 된다. 그 외에 업데이트가 더이상 지원되지 않은 이후부터는, 필자가 하루에도 수십에서 수백번 사용하게되는 핵심 기능인 간편검색의 경우 (C+m으로 매핑해둔다) 심상치않은 충돌이 보여 더이상 불안정한 시스템에 대해 인내하기 힘든 상황이었다.
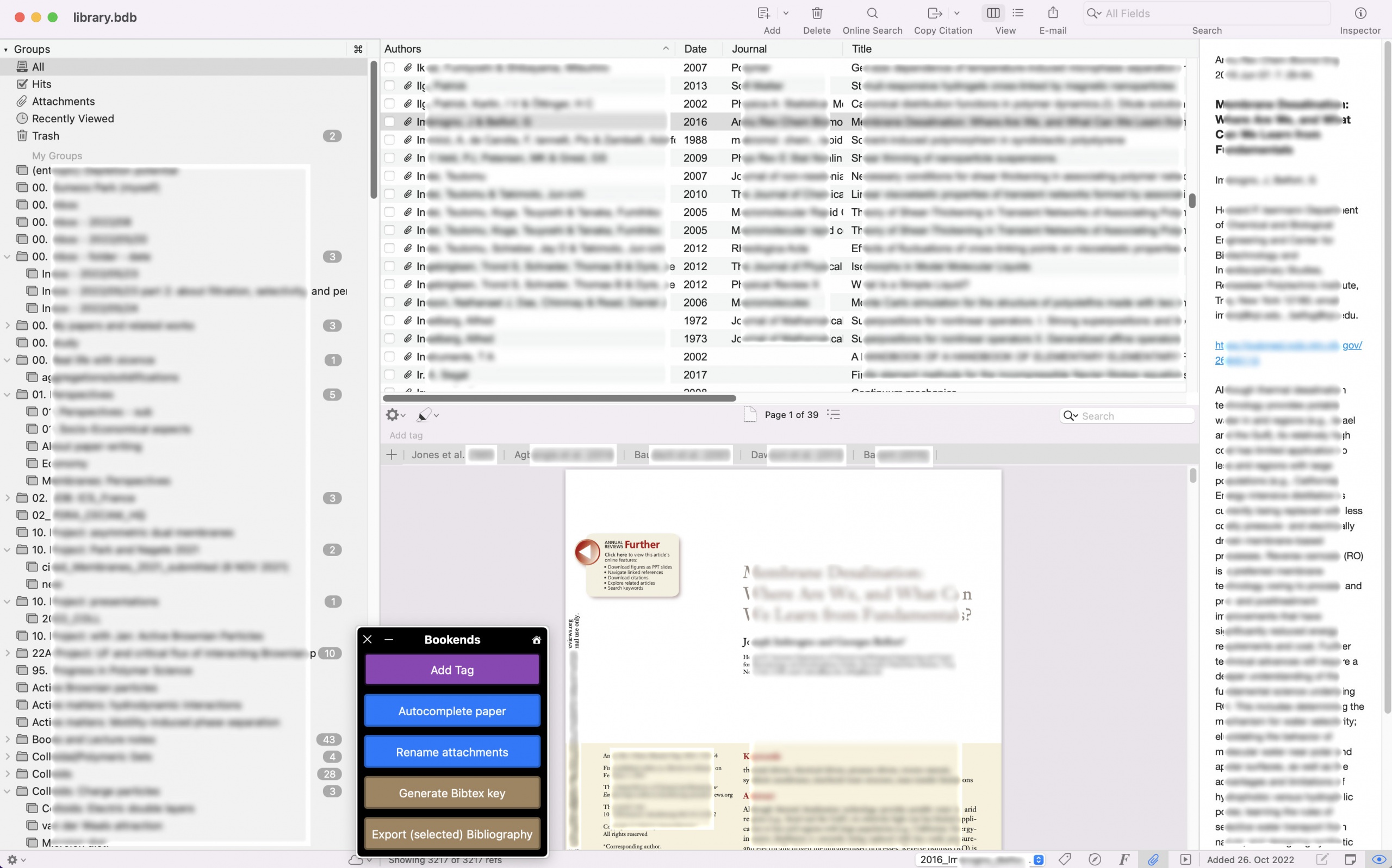
상당히 오랜 기간동안의 뜸들이기의 끝에, 새로운 시스템은 Bookends로 결정했다. 실제로 몇개월전에 다른 후보들과 비교 분석후에 구매를 했었고, 이번 부할절 휴가기간동안 주된 문헌들의 이전을 일단락 짓고 감상하고 있다. 필자생각에는 Bookends로 구축한 시스템은 DB와 첨부파일의 이원화를 통해 기존의 Papers와의 경계를 뚜렷하게 구분해준다. 여기에서 태그와 같은 시스템은 OS X의 시스템을 활용하게 되므로 전반적인 사용에 있어서 문헌파일 자체가 주인이고 Bookends DB의 경우 그 분류 및 활용도를 뒤에서 도와주는 느낌이다. 여기서 Papers와의 철학이 근본적으로 다르다고 느껴지는데, Papers는 자체 DB가 주체이고 문헌파일(주로 PDF)의 경우 첨부파일의 형식으로 각 DB에 딸린 존재로 인식된다. 이로인하여 Keyword에서 문헌파일에 직접 기입하는 Tag로 전향하게 되고 OS X 파인더/스폿라이트 등에서 손쉽게 관리할수 있으면서도 Devonthink로 index한 파일들에서도 태그가 살아있음으로 인하여 index이후 검색이 편리해지는 등 여러가지 장점이 존재한다. 다만 DB만 존재하는 문헌들 (실제로 옆에두고 참고하는 책들은 파일로 가지고 있지 않음)에 태그를 활용할수 없는 한계도 있는데, 해당 문제는 시간을 두고 천천히 해결해 볼 예정이다.
디테일로 들어가게 되면 여러가지 편의기능 및 클릭 혹은 드래그드랍등 사소한 일에서까지 Papers가 더 잘 설계되었다고 느끼는 것도 사실이다. 그럼에도 불구하고, 앱 전반적으로 느껴지는 겸손한 설계는 오히려 다른 소프트웨어를 사용할 수 있는 자유도를 제공해 주게 된다고 생각한다. 기본적으로 내부 PDF viewer는 미리보기 정도의 수준으로 가 썩 만족스럽지 않다. 비교적 강제적으로 직접적으로 다른 PDF viewer를 통해 문헌을 읽게 된다. 필자의 경우에는 주로 Preview와 PDF Expert를 이용하는데 (경우에 따라 다르다) 어느경우이든 서로 호환되는 하이라이트/메모가 가능하다는 장점이 있다. 물론, Papers의 경우에도 더블클릭시 자체브라우저가 아니라 외부 앱으로 연결되는 기능이 있기에 큰 차이점은 아니다. 여기에 태그 시스템의 경우 OS X의 태그시스템을 그대로 활용하면서 필자가 자주 사용하는 스폿라이트 및 디지털 연구노트로 활용하고 있는 Devonthink에서 index를 훌륭하게 서포팅 한다. 필자는 기본적으로 비선형일수 있는 지식정보의 데이터베이스를 선형구조로 엮어주는 핵심 기능을 Papers나 Devonthink에서 정의한 Group으로 보고 있다. 이는 폴더와 같이 트리 구조이기에, 어떤 작업을 하던 깊은 생각의 흐름을 도와주기 마련이다. 하지만 Bookends에서는 Folder와 Group을 구분지음으로서 트리구조의 계층한계를 부여한 느낌이고, 이게 개인 워크플로우에 어떤 장점 혹은 단점을 가져오게 될지는 미리 예측하기는 힘들다. 지금당장은, 이런 Group 시스템의 차이로 인해 문헌들의 이전에 이틀이 넘는 노가다가 필요했기에 좋다고만 말할수는 없는 상황이다 (아래 참조).
실제 이전은 Bookends에서 제공하는 방법에 따라 Papers 3에서 전체 첨부파일을 추출해서 새로운 저장소로 복사하고, Bookends 앱에서 제공하는 import from Papers기능을 활용해 데이터베이스를 추출해온다. 그리고 DB와 문헌파일 자체로 이원화된 시스템을 통해 문헌파일 저장소를 추출한 파일들이 쌓인 새로운 저장소로 지정해둔다. 이후 index의 편의를 위해 파일명을 쉽게 참조할수 있는 참고문헌의 기본 정보(년도, 저자, 저널, volume/issue, 그리고 제목)을 그대로 파일에 기입하게끔 셋팅해두면 Spotlight 및 Devonthink에서 직접적인 정보로 찾을수있게 도와준다. 이때 위에 언급한 Group 시스템의 차이로 인하여 이전 프로그램 사용시 트리형 계층구조인 Papers의 Group은 모두 Root Group만을 대표적으로 가지는 단일 계층의 Group들의 나열로 들어오게 된다. 즉 모든 핵심적인 이전은 자동화시스템으로 이루어져 있지만, 이 단순한 Group구성의 이전이 불가능하므로 먼저 Papers에서 그 동안의 그룹들에 전부 숫자를 붙여 구분할 수 있게 만든 다음 계층을 해체하여 모두 Root Group화 시키고 이를 이전시킨 Bookends에서는 다시 Folder를 생성해서 해당 Root Group들을 적절히 분류해서 넣어야 한다. 역시 Folder/Group의 분리화는 Group끼리의 Stack을 제공하지 않으므로 그 동안 미루고 미루던 정리작업을 같이 수행할 수 밖에 없었다. 물론 이러면서 옛날에 생각만 해둔 아이디어들을 재확인한 경험은 중요하지만, 이전작업이 끝나기 전까지 이를 더 확장할수없는것은 어쩔수없이 감내해야 하는 고난이다.
결과적으로 OS X에서 제공되는 tag시스템을 함께 공유하는 Bookends/Spotlight/Devonthink 시스템이 구성되었고 Ddevonsphere 서비스를 사용하는 필자의 경우 검색 접근성이 Spotlight, Bookends 간편검색, Devonsphere 기반의 (추정) 관계있는 문헌검색, Devonthink자체 인덱스 검색등으로 분화되었다. 일견 복잡해보일 수 있지만, 기존에도 Papers 간편검색 및 Devon시스템의 검색기능들을 조금씩 다른 이유로 활용했기에 크게 개의치 않고 사용한다. 언급했듯이, 실제 작업에서는 단순히 다양한 기능의 숫자가 많고 적음, 그리고 기능의 강력함등을 벗어나 작업의 습관들에 크게 의존하기에 큰 생각없이 중복적일수 있는 기능들을 상황의 흐름에 따라 다르게 사용하곤 한다. 요지는 지속적인 습관의 흐름(필자는 이를 워크플로우로 정의하고 있다)에 녹아있는 것이고, 이는 작업에만 집중할 수 있는 환경을 제공해 준다.
시작하는 글은 여기에서 마무리하고, 앞으로 새로운 글타래들은 기존의 워크플로우에서 어떻게 새로운 시스템이 녹아갔는지, bibtex와 Emacs의 reftex로의 전달환경, tag기반으로 진행되는 여러가지 분류들, Devonthink를 활용하는 기존의 짧은 연구노트들의 구조가 새로운 문헌파일들의 인덱스를 통해 활용할수 있는지 등을 기술해 볼 예정이다.
Leave a Reply